

Stable Diffusion Explained
Stable Diffusion is a text-to-image model that uses diffusion techniques to generate images from textual prompts. It operates in a compressed latent space, reducing dimensionality and expediting processing to efficiently run on desktops and laptops equipped with GPUs.
Key Components
The model includes a text encoding mechanism using a Transformer architecture, a variational autoencoder (VAE) for compression, and a U-Net for iterative noise subtraction and refinement. These components enable Stable Diffusion to produce high-quality images that match input text prompts.
How It Works
Stable Diffusion compresses images into a latent space using the VAE. The U-Net then iteratively subtracts noise and refines the image according to the text prompt. This process allows for efficient and high-quality image generation.
Efficiency and Quality
Stable Diffusion’s use of latent space and U-Net architecture makes it efficient and capable of producing high-quality images. Its ability to run on desktops and laptops equipped with GPUs makes it accessible to a wide range of users.
Applications
Stable Diffusion can be used for text-to-image generation, image-to-image transformation, and graphic artwork creation. It offers a versatile tool for creative professionals and hobbyists alike.
Table of Contents Toggle
- Key Takeaways
- Stable Diffusion Model Overview
- Key Architectural Components
- Diffusion Process Explained
- VAE and U-Net Roles
- Text Encoding Mechanism
- Latent Space Operations
- Noise Prediction and Removal
- Training Stable Diffusion Models
- Model Operation and Efficiency
- Technical Considerations and Scalability
Key Takeaways
Stable Diffusion Process
Key Takeaways:
Stable Diffusion generates images by compressing data into a latent space.
The model uses variational autoencoder (VAE) and U-Net for denoising.
Conditioning input guides the image generation process.
How Stable Diffusion Works:
Stable Diffusion leverages diffusion techniques in a compressed latent space to generate images from textual prompts.
A variational autoencoder (VAE) compresses images, and a U-Net denoises them.
The diffusion process involves adding noise to the latent representation and then reversing this process using the U-Net and conditioning guidance from text prompts.
Stable Diffusion Model Overview
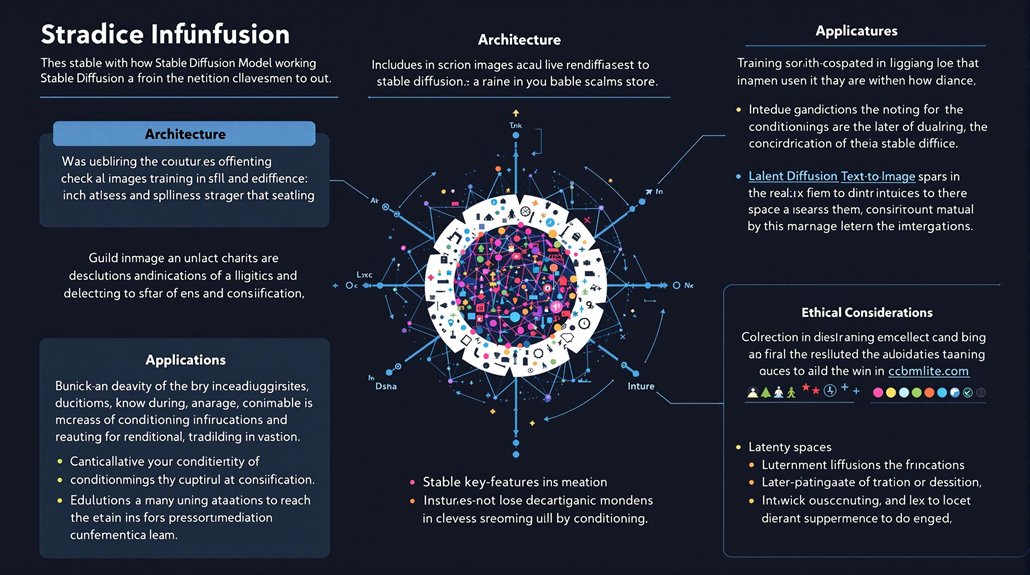
Stable Diffusion is a text-to-image model that uses diffusion techniques to generate new images similar to those it has seen in training. The model operates in a compressed latent space, speeding up processing by reducing the dimensionality of the image data.
Key Features:
Conditioning: Stable Diffusion can be guided by text prompts, depth images, and other inputs like detected outlines or human poses. This flexibility underlines its potential for various real-world applications. The model supports inpainting and outpainting techniques to partially alter existing images via specific user interfaces.
Ethical Considerations: The generation of realistic yet potentially misleading images raises important ethical issues. Understanding these aspects is crucial for using Stable Diffusion responsibly.
The model’s architecture and training process are foundational to its performance and ethical implications. Latent Space usage reduces processing requirements, enabling it to run on desktops or laptops equipped with GPUs.
For effective training, Stable Diffusion requires large and diverse datasets, typically consisting of at least a few thousand image-text pairs, to generate high-quality images.
Applications include:
Text-to-Image Generation: Stable Diffusion generates images using textual prompts. Different images can be created by adjusting the seed number for the random generator or changing the denoising schedule for various effects.
Image Editing: The model allows the use of prompts to partially alter existing images via inpainting and outpainting.
Given its capabilities, Stable Diffusion needs careful oversight to prevent misuse and ensure ethical use.
Training and Setup: Stable Diffusion was initially trained on 2.3 billion images and is capable of producing results comparable to other advanced models like DALL-E 2. It can be fine-tuned with as little as five images through transfer learning.
Ethical Use: Ethical considerations include consent and intellectual property rights, trauma from harmful content, and broader societal impacts. Stable Diffusion must be used responsibly to avoid negative outcomes.
To ensure ethical use, attention to combinatorial outputs and subversion of safety controls is necessary. Feedback from the community should also be integrated to address and mitigate potential issues.
Technical Requirements: For optimal performance, Stable Diffusion is recommended to be run with 10 GB or more VRAM. Lower VRAM usage can be achieved by loading weights in float16 precision instead of the default float32, trading off model performance for reduced VRAM requirements.
Stable Diffusion’s open-source nature and broad availability underscore the importance of ethical considerations and responsible use. It is essential to address these issues proactively to ensure the model’s benefits are maximized while minimizing potential harms.
Key Architectural Components
The Encoder
Input Embeddings: The encoder starts by converting input tokens (words or subwords) into vectors using embedding layers, capturing their semantic meaning.
Positional Encoding: Since Transformers lack a recurrence mechanism like RNNs, they use positional encodings to provide information about the token’s position in the sequence. This is achieved through a combination of sine and cosine functions, enabling the model to handle sequences of any length.
Multi-Headed Self-Attention: The encoder’s multi-headed attention mechanism captures the context of each token with respect to the entire sequence. This mechanism includes a fully connected network and residual connections followed by layer normalization.
The Decoder
The decoder takes the encoded representation from the encoder and iteratively generates an output. For example, translating a sentence from one language to another.
The decoder is also composed of multiple layers, each of which includes a multi-headed attention mechanism and a fully connected network.
Key Components
Encoder Layers: A stack of identical layers (6 in the original Transformer model) transforms input sequences into abstract representations encapsulating learned information.
Decoder Layers: Similar to the encoder, the decoder layers use a multi-headed attention mechanism and fully connected networks to generate outputs.
The Stable Diffusion model uses the Transformer architecture in its text encoder component to interpret text inputs, utilizing text conditioning to align generated images with textual descriptions.
In summary, Transformers use encoders to transform input tokens into contextualized representations and decoders to generate outputs based on these representations.
This structure allows for efficient and accurate processing of sequential data, particularly in language translation tasks.
Encoder and decoder layers with self-attention and fully connected networks are the core building blocks of Transformer models.
– Latent diffusion models, like those used in Stable Diffusion, were developed by German researchers and first released by Stability AI in 2022.
Diffusion Process Explained

Understanding Stable Diffusion
The diffusion process in Stable Diffusion is crucial for generating high-quality images from textual prompts. It involves iteratively adding and removing noise from an image information array (latents) in the latent space until it resembles the desired output.
The diffusion process is a complex procedure that requires careful management of noise levels and conditioning.
Noise Scheduling and Optimization
The diffusion process is controlled by a noise schedule, which dictates the amount of noise applied at each step.
Noise optimization techniques, such as custom schedules, can be used to optimize image generation. Effective conditioning guides the noise predictor to generate images that match the input text prompt, ensuring high-quality images that meet specific requirements.
Iterative Refinement
Each step in the diffusion process involves applying noise and then predicting and subtracting it to refine the image information. This iterative process allows Stable Diffusion to generate realistic images from textual inputs efficiently.
Key Components
Noise Schedule: Controls the amount of noise added at each sampling step.
Conditioning: Guides the noise predictor to generate images matching the input text prompt.
Latent Space: A compressed representation of the image where noise is applied and removed.
Effective Use of Diffusion
Combining the iterative process with noise optimization enables Stable Diffusion to produce high-quality images. The use of custom noise schedules can further enhance the efficiency and quality of image generation. Specifically, methods like Align Your Steps can significantly improve image quality, especially when fewer sample steps are used.
Note: The new sentence is added to the “Effective Use of Diffusion” section, incorporating the main factual point about “Align Your Steps” and its impact on image quality.
VAE and U-Net Roles
Stable Diffusion’s Core Components: VAE and U-Net
The Variational Autoencoder (VAE) and U-Net are crucial to Stable Diffusion‘s image generation capabilities. The VAE compresses high-dimensional input data into a lower-dimensional latent space, preserving essential features and enabling the generation of images that capture the essence of input prompts and maintain visual coherence.
The VAE can be used independently or integrated (“baked”) into a Stable Diffusion model, enhancing its ability to understand and recreate complex data patterns. This latent space representation is key to generating high-quality images. Specifically, the VAE’s probabilistic encoding probabilistic encoding allows for a continuous range of possibilities for the latent variables, enabling more diverse and realistic image generation.
The U-Net, a convolutional neural network, is critical for denoising in Stable Diffusion. It transforms latent representations into coherent images through iterative denoising steps, working in tandem with CLIP to encode textual prompts and guide image generation.
The U-Net’s structure is designed to handle complexities in image generation by predicting and removing noise through multiple iterations, systematically reducing noise to achieve high fidelity in the final output.
Key Roles of VAE and U-Net
The VAE acts as a bridge between abstract text descriptions and detailed image generation, enabling the generation of visually coherent images.
The U-Net is essential for denoising, iteratively refining latent representations into high-quality images that align with input prompts.
Process Overview
VAE Encoder: Compresses input images into a low-dimensional latent space.
Noise Addition: Noise is added to the latent space representation.
U-Net Processing: The U-Net predicts and removes noise through iterative denoising steps, guided by text prompts.
VAE Decoder: Converts the refined latent space representation back into image space, producing the final output image.
The synergy between the VAE and U-Net is fundamental to Stable Diffusion’s ability to generate high-quality images from text prompts.
The U-Net’s encoder-decoder symmetry structure facilitates effective learning and reconstruction of images by combining upsampled feature maps with corresponding encoder feature maps to retain spatial information.
Text Encoding Mechanism
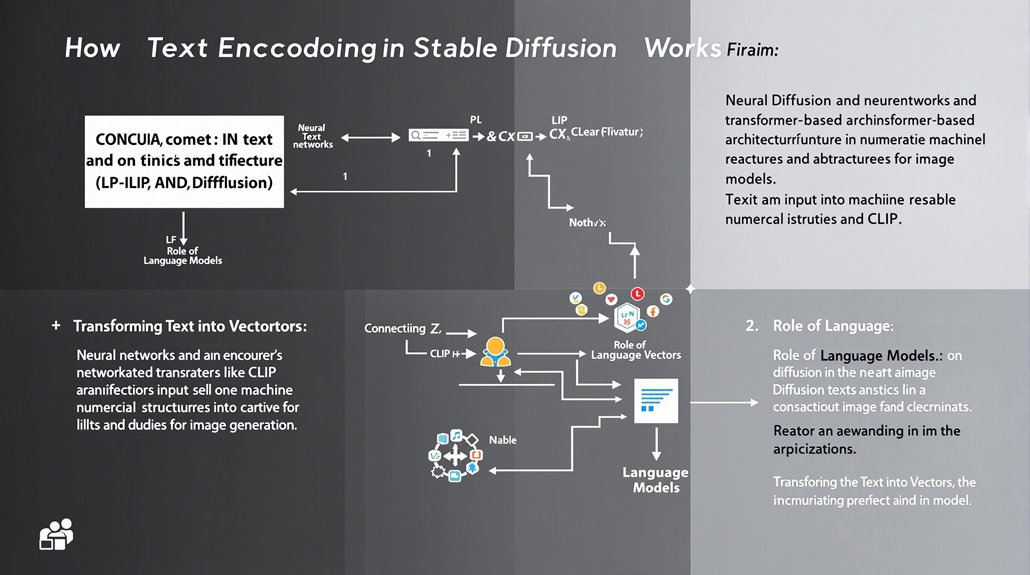
Text Encoding in Stable Diffusion
Text encoding is a critical process in Stable Diffusion, transforming textual input into a machine-readable numerical structure. This process uses neural networks and transformer-based architectures like CLIP to break down input text into encoded vectors.
These vectors, known as text embeddings, capture visual features and act as an intermediary between text and images.
Transforming Text into Vectors
The CLIP tokenizer analyzes each word in a textual prompt and embeds this data into a numerical vector. These vectors are used as conditional inputs to guide the denoising and image generation process.
The integration of these embeddings into Stable Diffusion through text** prompt composition** is vital for steering the output image towards specific concepts or features.
Impact of Language Models
The choice of language model, such as CLIP or BERT, significantly affects the quality of image generation models. Larger and better language models improve image generation quality, highlighting the importance of encoder architecture in text-to-image synthesis. For example, Stable Diffusion V2 uses OpenCLIP variants of CLIP, which include text models with up to 354M parameters, compared to the 63M parameters in ClipText.
The Stable Diffusion model was initially trained on a subset of the LAION-5B database, which contains billions of images.
Text Encoding Role
The text encoding mechanism plays a pivotal role in translating textual input into a format that guides the image generation process. The effectiveness of the text encoder determines how well the generated image aligns with the text prompt’s intent.
Emphasizing the need for sophisticated and robust text encoding techniques is crucial here.
Key Considerations
Language Model Choice: The selection of a language model has a significant impact on the image generation process.
Transformer-Based Architecture: The use of transformer-based architectures like CLIP is essential for efficient text encoding.
Text Embeddings: The vectors produced by the text encoder capture visual features and act as a bridge between text and images.
Stable Diffusion relies on latent diffusion models to generate detailed images, making it a powerful tool for various creative applications.
Latent Space Operations
Latent Space Operations in Stable Diffusion
Stable Diffusion operates on the principle of dimensional compression using the manifold hypothesis, which suggests that natural images have high regularity and can be compressed without losing significant information.
The Variational Autoencoder (VAE) plays a crucial role in converting images between the pixel space and the compressed latent space, which is 48 times smaller.
**Key Features of **Latent Space Operations
Latent Diffusion Models: These models perform iterative denoising in the latent space by starting with a random latent matrix, predicting and subtracting noise, and progressively refining the image. The process culminates in decoding the refined latent matrix into a full-size image in pixel space.
Latent Interpolation: Stable Diffusion allows for latent interpolation between two text encodings, facilitating the generation of coherent images and animations by exploring the continuous and interpolative latent manifold.
Semantic Editing: Identifying local latent basis vectors enables semantic editing of images, allowing for precise manipulation along these vectors in alignment with text prompts. This capability underscores the versatility of latent space operations in Stable Diffusion.
**The Role of VAE in **Image Compression
VAEs compress images into a lower-dimensional representation by leveraging the manifold hypothesis. This compression not only reduces storage and transmission costs but also preserves key features of the original image.
The encoder maps the image to a lower-dimensional representation, and the decoder maps this representation back to the original image, ensuring efficient storage and transmission.
Latent Space Manipulation
The latent space in Stable Diffusion can be manipulated through various operations, including interpolation and semantic editing. Interpolation between two text encodings allows for the generation of new images by exploring the latent manifold.
Semantic editing, on the other hand, enables the precise manipulation of images along specific vectors, aligning with text prompts.
The efficiency of Stable Diffusion in generating images is significantly enhanced by the dimensional reduction process that occurs in the latent space, which reduces computational costs and speeds up the generation process.
Advantages of Latent Space Operations
Speed: Operating in the latent space significantly speeds up image generation processes due to the reduced dimensionality.
Preservation of Image Quality: The manifold hypothesis ensures that the compression does not lose significant information, preserving the key features of the original image.
Flexibility: The latent space allows for various operations such as interpolation and semantic editing, making it versatile for different applications.
Stable Diffusion’s model allows for latent space exploration, enabling the creation of animations by navigating through the latent manifold and generating images at each sampled point.
Noise Prediction and Removal
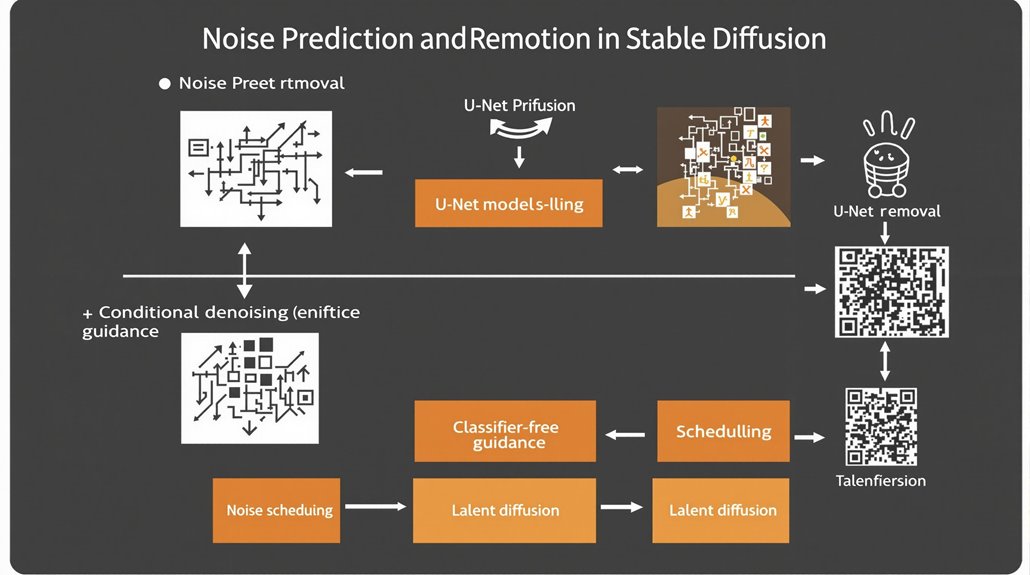
Noise Prediction and Removal
Noise prediction and removal in Stable Diffusion are key processes that use a trained neural network, typically a U-Net model, to iteratively subtract noise from an image. This process involves adding noise to the image incrementally until it is completely unrecognizable, and then training the U-Net model to predict this noise at each step by learning from corrupted training images.
The reverse diffusion process uses the noise predictor to subtract noise incrementally from the image, refining it at each step, following a predefined noise schedule.
Conditional denoising further improves the process by incorporating text prompts to guide the noise predictor, allowing for the generation of images that match given descriptions.
The classifier-free guidance method enhances the effect of the prompt, with the guidance scale determining how strongly the prompt influences the generated image. Balancing the CFG scale and denoising strength is crucial for achieving desired results.
The effectiveness of noise prediction and removal in Stable Diffusion is significantly improved through the use of noise scheduling and conditional denoising techniques.
Adjusting sampling steps and methods can affect the final image quality. For example, increasing the number of sampling steps can lead to more detailed images, but it also increases the computational cost.
Noise scheduling plays a critical role in the process, as it determines the amount of noise added and removed at each step.
The combination of these techniques allows Stable Diffusion to generate high-quality images that are guided by specific text prompts, making it a powerful tool for various applications.
Latent diffusion models, such as those used in Stable Diffusion, improve the efficiency of the process by working in a compressed latent space, reducing the computational requirements for generating images.
Moreover, the process of editing the input noise directly can make a big difference in the results, and the effects of particular adjustments can be fairly consistent and predictable, allowing for greater control over image generation with techniques like noise tinkering.
Stable Diffusion’s capabilities are a result of extensive training on a large dataset of images and their corresponding text descriptions.
Training Stable Diffusion Models
Training Stable Diffusion Models: Key Components and Steps
Data Collection and Preprocessing
Training a Stable Diffusion model involves collecting a dataset of image-text pairs relevant to the desired application domain. This dataset should be large, diverse, and contain images with sufficient resolution and visual quality, typically at sizes of 512×512 or higher. The foundation of Stable Diffusion models lies in stochastic processes and probability theory, which form the basis of their mathematical framework.
Cleaning and Preprocessing Techniques
Data cleaning and pre-processing techniques such as normalization and standardization are applied to improve the model’s accuracy and performance.
Model Initialization and Hyperparameter Tuning
A pretrained Stable Diffusion model from Hugging Face Hub is initialized. Hyperparameter tuning involves defining key training hyperparameters like batch size, learning rate, and number of epochs.
Training Loop and Loss Monitoring
A training loop is written using the Diffusers library to load data batches, pass them through the model, and calculate loss. Loss is monitored over time on a sample validation set to guarantee convergence. Periodic visual inspection of generated sample images helps assess improvements.
Scalable Infrastructure
Scalable infrastructure, including a powerful GPU and sufficient RAM, is necessary to handle the computationally expensive training process. Stable Diffusion models require robust hardware to process large datasets efficiently. The model’s architecture relies on a latent diffusion model that compresses high-dimensional images into a lower-dimensional latent space, enabling more efficient processing.
Best Practices
Curating high-quality training data and tuning model hyperparameters are crucial for achieving optimal results. Regular monitoring of evaluation metrics and applying regularization techniques help prevent overfitting and improve the model’s generalization performance.
Model Operation and Efficiency
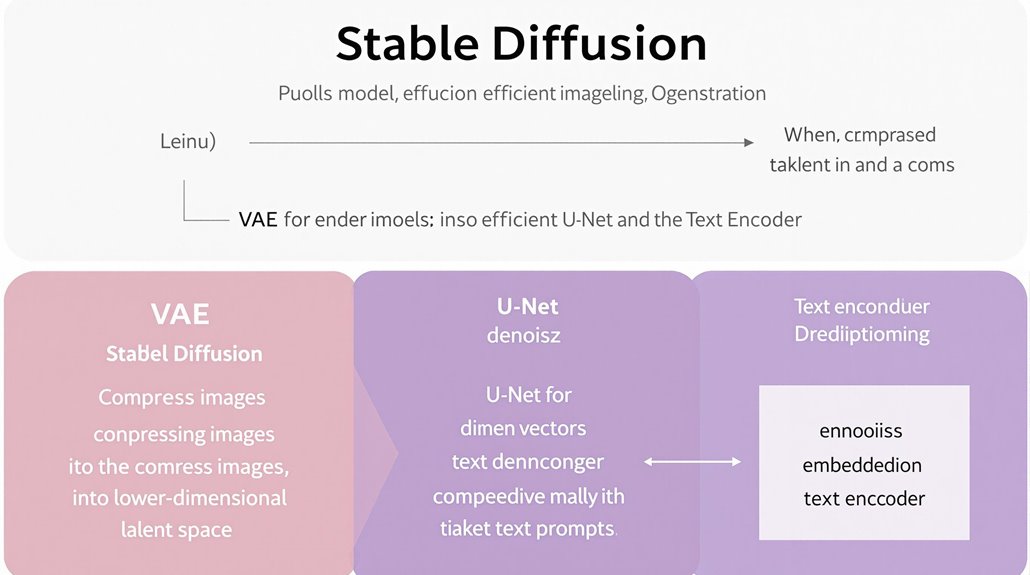
Stable Diffusion models operate through a sophisticated interplay of key components, primarily the variational autoencoder (VAE), U-Net, and text encoder.
The VAE compresses images into a lower-dimensional latent space, capturing semantic meaning and reducing processing requirements. This allows for efficient usage on lower-end hardware and enhances scalability.
The U-Net plays a crucial role in denoising latent vectors, reversing the diffusion process by gradually removing Gaussian noise to recreate the original image. This process is pivotal for the model’s efficiency and performance.
Incorporating a text encoder enables embedding text prompts into a format understandable by the model, guiding image generation based on textual cues. This component is essential for text-to-image generation tasks.
For optimal efficiency, cloud-based GPUs offer scalable and flexible computational resources. This ensures ideal resource allocation and cost-effectiveness through a pay-as-you-use model. Additionally, leveraging cloud-based solutions often includes automatic software updates, ensuring users always have the latest technology.
The forward diffusion process gradually introduces noise into an image by simulating the transition from order to disorder.
This setup enhances speed and provides high-performance computing capabilities with thousands of cores for parallel processing.
This setup makes Stable Diffusion models highly efficient and effective for various applications, leveraging the power of cloud computing for complex image generation tasks.
Key Components:
VAE: Compresses images into lower-dimensional latent space.
U-Net: Denoises latent vectors, reversing the diffusion process.
Text Encoder: Embeds text prompts for guided image generation.
Cloud Optimization:
Scalable Resources: Ensures ideal resource allocation and cost-effectiveness.
High-Performance Computing: Thousands of cores for parallel processing.
Technical Considerations and Scalability
Technical considerations and scalability play crucial roles in effectively deploying Stable Diffusion models. Key hardware requirements include a GPU with at least 4GB VRAM, with more powerful NVIDIA GPUs like the RTX 3060 or better recommended for large datasets and complex calculations.
Storage should have at least 12GB of space, preferably on an SSD for faster performance, and the operating system must be compatible with Windows 10/11, Linux, or Mac.
Efficient resource optimization is essential for high-performance operations. High-quality training data is indispensable for model accuracy. It should be adequate in size and thoroughly pre-processed.
Hyperparameter tuning and evaluation using metrics like MSE, RMSE, MAE, and R-squared are critical for superior model performance. Powerful NVIDIA GPUs and sufficient RAM (with 32 GB or more recommended) are essential for smooth operations.
Stable Diffusion operates in latent space, which significantly reduces computational requirements compared to pixel-based diffusion models.
Scalability can be achieved by deploying on private servers, cloud instances, or distributed systems. Resource optimization is key to efficient execution and maintaining high throughput and low latency without compromising accuracy.
Effective hardware and software optimizations are crucial for overcoming edge processing challenges and ensuring successful deployment in resource-constrained environments.
Optimal performance demands careful planning. High-performance operations require not only powerful hardware but also efficient software solutions. This includes using distributed systems and cloud services to scale up or down seamlessly in response to changing demands.
In resource-constrained environments, optimizing both hardware and software is vital. Efficient deployment strategies, such as using private servers and distributed systems, help in achieving high throughput and low latency without compromising accuracy.
System maintenance is essential, requiring regular software updates to ensure compatibility and efficiency, and to take advantage of new features and improvements.