

Stable Diffusion models work through an architecture combining U-Net and Variational Autoencoder components to create images. The system needs specific hardware like a minimum 4GB VRAM and NVIDIA RTX 3060+ GPU.
The implementation process requires careful data preparation and parameter adjustments, with learning rates set between 1e-5 to 5e-6. Visual quality assessment and prompt accuracy measurements help track the model’s performance.
Memory management and technical optimization ensure the model runs efficiently and produces consistent results. These practical steps help users understand and work with AI image creation tools effectively.
Table of Contents Toggle
- Key Takeaways
- Understanding Stable Diffusion Core Components
- Data Preparation and Processing
- Setting Up Training Environment
- Fine-tuning Model Parameters
- Monitoring and Optimizing Performance
Key Takeaways
U-Net and VAE process image tasks at 512×512 resolution.
NVIDIA RTX 3060 needs 16GB RAM for basic operation.
Set learning rates between 1e-5 for stable model training.
Understanding Stable Diffusion Core Components
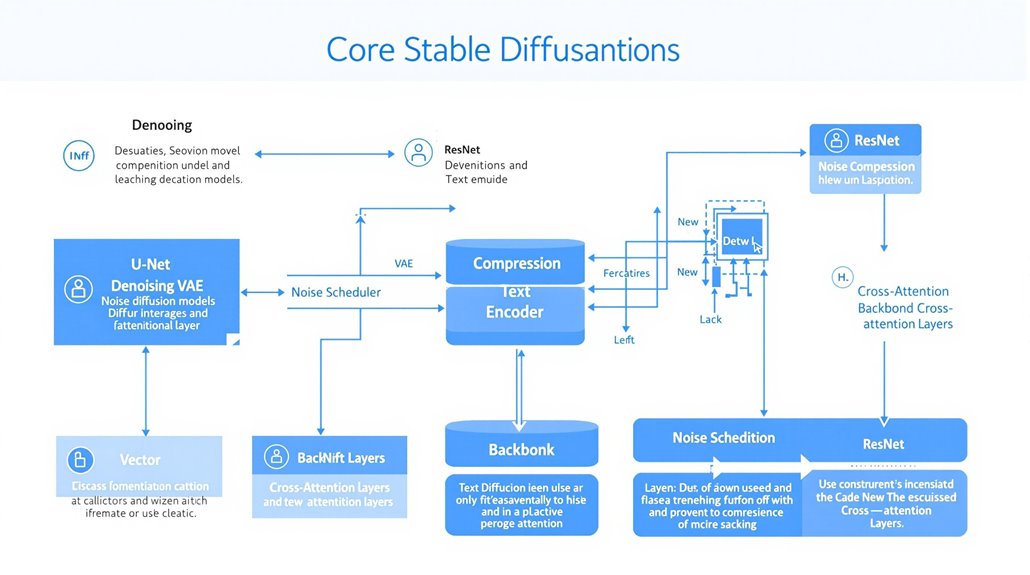
Core Components of Stable Diffusion Models
The U-Net and Variational Autoencoder (VAE) work as primary components in Stable Diffusion’s architecture. The U-Net processes denoising tasks on latent vectors, while the VAE manages image compression and reconstruction between different dimensional spaces. The model utilizes a ResNet backbone in its U-Net architecture for enhanced processing capabilities.
A noise scheduler introduces Gaussian noise patterns during forward diffusion, coordinating with the text encoder to process input prompts. This structured approach allows precise control over the image generation sequence through mathematical transformations of latent space vectors.
The **denoising **diffusion probabilistic models create a foundation for precise vector manipulation and refinement. Through systematic processing, the components transform abstract mathematical representations into detailed visual outputs that match user specifications. The model leverages cross-attention layers to effectively condition the denoising process on text prompts and other modalities.
Data Preparation and Processing
High-quality datasets form the base for training Stable Diffusion models. The process starts with choosing samples that show variety while meeting quality standards.
The critical step of data normalization helps prepare samples for optimal processing. Data cleaning removes problematic entries and uses specific techniques to expand dataset variety. Image and text pairs go through checks to ensure they match correctly, while efficient processing methods help manage large amounts of data. Missing value handling improves overall data quality through careful imputation techniques.
The **training **system uses controlled image breakdown methods through mathematical equations. Regular checks and adjustments of model settings help create better results, making sure the foundation stays strong for building reliable Stable Diffusion models.
Setting Up Training Environment
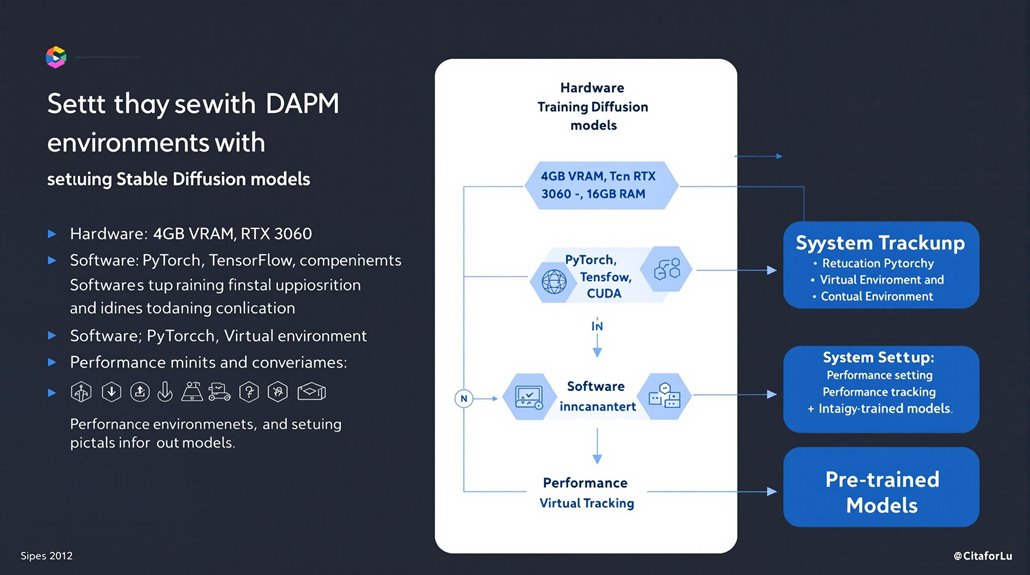
Setting Up Your Training Environment
Effective image generation requires specific hardware and software configurations. A minimum setup includes 4GB VRAM, preferably with an NVIDIA RTX 3060 or better GPU, paired with 16GB RAM and 12GB SSD storage. Virtual environments are recommended to avoid dependency conflicts and maintain clean installations.
Essential machine learning tools include PyTorch, TensorFlow, or JAX, with proper GPU drivers supporting CUDA. Google Colab or Jupyter Notebooks offer practical platforms for development, while the Diffusers library supports model development. The process of training from scratch requires significant computational power and technical expertise.
Training success depends on careful system optimization. This includes appropriate storage allocation, parameter adjustment, and proper model regularization to maintain stable performance throughout development cycles.
Regular performance tracking helps identify necessary adjustments to improve model accuracy. Pre-trained models reduce resource usage and speed up development, making them valuable starting points for new projects.
Fine-tuning Model Parameters
Setting up Stable Diffusion models requires precise parameter control for optimal results. The learning rate works best between 1e-5 and 5e-6, while batch sizes of 8-16 provide balanced processing based on GPU capabilities. High-quality GPU memory is essential for efficient model training and parameter adjustments.
DreamBooth and LoRA represent two distinct parameter modification methods. Training typically requires only a dozen images of the target subject. These tools manage specific image sets and layer adjustments, reducing both training time and data needs.
Parameter success depends on visual output quality and prompt response accuracy. Continuous monitoring paired with proper dataset management creates reliable model adaptation results.
Monitoring and Optimizing Performance
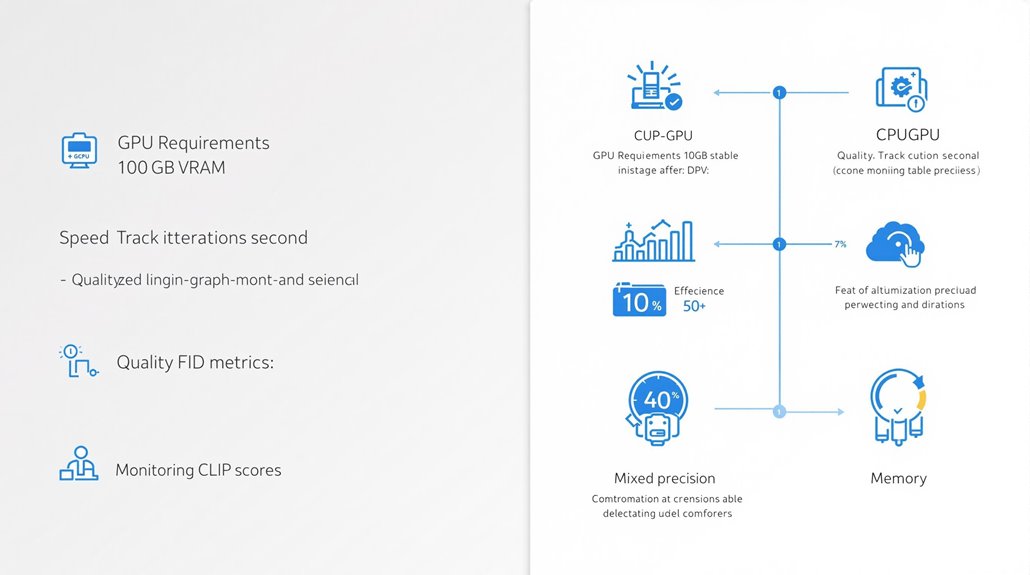
Performance Tracking for Stable Diffusion
Core monitoring tools measure speed, quality, and efficiency through specific data points. Speed measurements track iterations per second, while quality assessments use FID and Inception Score metrics to evaluate image outputs. Selecting Euler sampling provides the most consistent benchmarking results across different systems.
Technical setup requires proper hardware planning with GPU considerations. A minimum 10GB VRAM capacity supports basic 512×512 image creation, while higher specifications allow advanced operations. Early stopping helps prevent model overtraining during extended training sessions.
Memory management tactics improve model operations through precise adjustments. Mixed precision training reduces resource usage, while proper batch size configuration maximizes available GPU power.
Data analysis helps maintain optimal model function through ongoing evaluation. Regular checks of loss metrics and sample image quality ensure consistent performance, with CLIP scores measuring text-to-image accuracy.
Resource allocation impacts both cost and output capabilities significantly. Strategic hardware choices and infrastructure planning help maintain sustainable operations while meeting quality standards.