

Text to Video with Stable Diffusion
To create videos from text descriptions using Stable Diffusion, tools like AnimateDiff and Deforum are available. These platforms integrate Stable Diffusion models with separate motion prediction modules to generate sequences of images that form cohesive video content.
**AnimateDiff: **Predicting Motion Between Frames
AnimateDiff generates animated videos from text descriptions by predicting motion between frames. This tool combines text prompts with learned motion patterns to create high-quality videos.
**DeForum: **Applying Transformations for Motion Illusions
DeForum, on the other hand, applies 2D and 3D transformations for motion illusions and frame interpolation. By specifying frame numbers, text prompts, and motion modules, users can create detailed and animated videos.
Key Features
Seamless Integration: Both tools seamlessly integrate with Stable Diffusion models.
Easy to Use: Creating videos using these tools involves selecting a model and adding text prompts, making them accessible even to novice users.
Advanced Customization: Users can specify frame numbers, text prompts, and motion modules for more detailed control over the animation.
Table of Contents Toggle
- Key Takeaways
- Stable Diffusion Basics
- GUI Setup
- Using AnimateDiff
- ModelScope Configuration
- Deforum for Videos
- Selecting Stable Diffusion Models
- Configuring Video Settings
- Generating Videos
- Improvement Techniques
- Practical Applications
Key Takeaways
Text to Video with Stable Diffusion: Key Steps
Install Stable Diffusion Web UI and extract it to a desired folder, launching it with the ‘webui-user.bat’ file.
Enable Extensions: Add extensions like ModelScope and Deforum to handle video transitions and animations.
Configure Video Settings: Use AnimateDiff to generate animated videos by specifying a pre-trained motion module, frame numbers, and text prompts.
Key Points:
Install Stable Diffusion Web UI to create the base environment.
Choose Extensions: Select between AnimateDiff for pre-trained motion modules and Deforum for 2D and 3D video transformations.
Adjust Video Parameters: Control video quality by setting resolution, denoising strength, and noise multiplier for smooth animation.
Stable Diffusion Basics
Stable Diffusion Basics
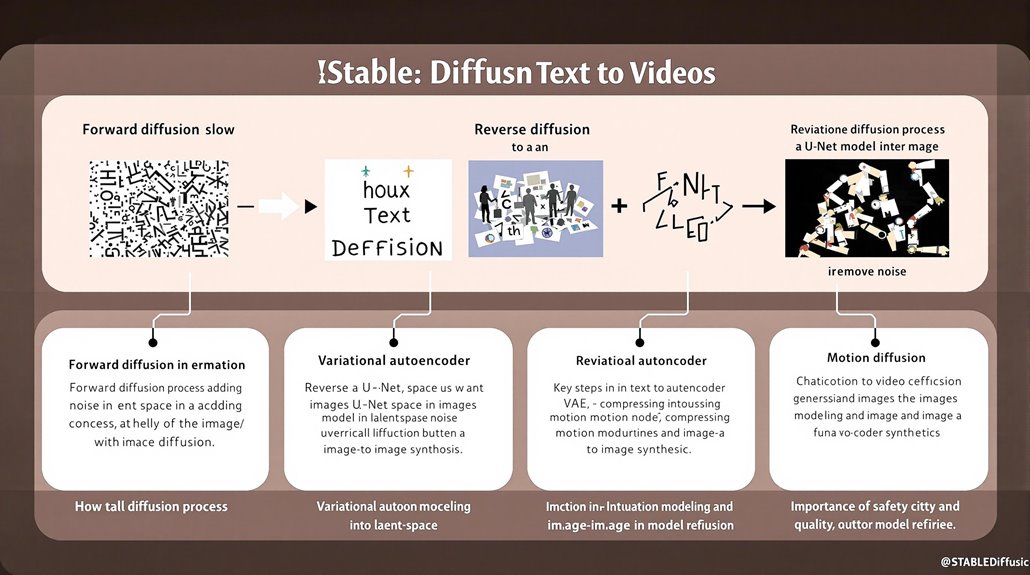
Stable Diffusion employs two key processes: forward diffusion and reverse diffusion. The forward diffusion process degrades an original image by adding random noise, while the reverse diffusion process restores the image to its original form by removing this noise.
**Latent Space and **Noise Prediction
This process uses latent space, where images are compressed by a variational autoencoder (VAE) into a smaller form. This reduces processing requirements and facilitates efficient noise prediction and denoising.
The U-Net model predicts noise in latent space, enabling the reverse diffusion process.
**Image Generation and **Video Creation
By repeating these steps, Stable Diffusion refines the denoising process, generating high-quality images from text prompts. This foundation in image generation is crucial for extending Stable Diffusion capabilities to video creation.
Noise prediction in latent space allows for precise control over the denoising process, ensuring detailed images.
Adapting to Video Applications
Stable Diffusion’s approach to image generation is directly applicable to video creation. The model can be adapted to multi-view synthesis from a single image with finetuning on multi-view datasets, making it versatile for various downstream tasks.
From Text to Video
By leveraging the principles of Stable Diffusion, text-to-video models like AnimateDiff and Deforum utilize motion modeling and image-to-image synthesis to transform text descriptions into videos.
These models achieve video consistency by injecting motion into the noise predictor U-Net or using img2img across frames.
Key Components of Stable Diffusion
Latent Space: Compresses images for efficient processing.
U-Net Model: Predicts noise in latent space for reverse diffusion.
Variational Autoencoder (VAE): Encodes images into latent space.
Noise Prediction: Ensures precise control over denoising for high-quality images.
Training Overview
Stable Diffusion models are trained using a process that involves teaching a neural network model to predict the noise added to an image. This is done by generating a random noise image and corrupting the training image with it, then fine-tuning the model to estimate and remove this noise. Stable Diffusion models can be extended to video generation using additional techniques like motion modeling.
Applications Beyond Images
The foundational work of Stable Diffusion in image generation lays the groundwork for its extension into video creation. This model’s adaptability to various tasks highlights its potential for diverse applications in advertising, education, entertainment, and beyond.
Model Capabilities and Limitations
Stable Diffusion models, such as those released by Stability AI, are competitively performing in user preference studies and are adaptable to numerous video applications. However, they emphasize the importance of safety and quality feedback for refinement before commercial use.
Stable Diffusion’s Impact
The model’s use of latent space and efficient noise prediction has significantly reduced processing requirements, making it accessible and versatile for a range of applications, including text-to-image, image-to-image, and text-to-video transformations.
GUI Setup
Setting Up the GUI
Setting up the Stable Diffusion GUI involves several crucial steps to ensure seamless functionality. To begin, install the Stable Diffusion Web UI, which serves as the core interface for creating and managing AI-generated content.
Key Installation Steps:
Install Python on the system to support the GUI. Download and place the Stable Diffusion Web UI in the desired folder, then launch it by running the ‘run.bat’ file[1,4].
Configuring the GUI:
Enable key settings like Upcast Cross Attention Layer to float32 for better performance. Specify frame numbers and corresponding text prompts, adjusting sampling steps and methods for desired output quality.
Adding Extensions:
Install necessary extensions such as Control Net from the Stable Diffusion Web UI’s Extensions tab. Control Net is essential for smoother transitions and can be downloaded from Hugging Face. For video handling, FFMpeg is required. The Control Net extension is particularly important for video content creation, as it allows for smoothened frame transitions.
Customizing the GUI:
Install additional extensions like SD-CN-Animation for video content creation and Text2Video for text to video synthesis. Ensure proper model file placement and apply changes by restarting the UI[2,3].
Setting Model Parameters:
Choose the correct Stable Diffusion model from the dropdown menu and refresh the list if necessary. Input detailed and specific prompts in the text box to achieve desired image results.
Key Considerations:
Ensure Python and necessary extensions are installed.
Adjust settings and sampling steps for optimal performance.
Use Control Net for smoother transitions.
Proper model file placement and UI restart are essential for effective customization.
Using AnimateDiff

Using AnimateDiff to Convert Text Prompts into Videos
With AnimateDiff, you can seamlessly integrate pre-trained motion modules with Stable Diffusion models to generate animated videos from text prompts. This process involves leveraging a motion module to learn general motion patterns from real-world videos.
Enabling AnimateDiff
Navigate to the txt2img page and enable AnimateDiff. Select a pre-trained motion module, such as the V3 motion module, to apply learned motion patterns to your video.
Configuring Settings
Choose your desired settings, including the number of frames and FPS. These parameters control the length and speed of the generated video.
Entering Text Prompts
Enter a detailed text prompt to direct the animation. You can also use optional negative prompts to further refine the animation’s style and content.
Enhancing Video Stylization
To enhance video stylization, consider using techniques like Motion LoRA and ControlNet. These tools allow for more precise control over animation dynamics and motion patterns.
Advanced Options
Additional features like prompt travel and reference videos can be used to guide the animation and improve motion variety. These tools help create more diverse and complex animations. AnimateDiff can also generate seamless looping animations, which are particularly useful for creating continuous animations without abrupt endings seamless looping. For a more robust setup, ensure the installation of Fizz Nodes to streamline batch prompt scheduling and fine-tune animation sequences.
Generating Animated Videos
Once you have configured the settings and entered your text prompt, press the generate button to create a short animated video. This video will reflect the concepts and motion patterns described in your text prompt.
ModelScope Configuration
Configuring ModelScope for Text-to-Video Generation
ModelScope is a sophisticated text-to-video model that uses diffusion-based techniques to generate videos from text descriptions. It decomposes noise into base and residual components, which allows for frame consistency and dynamic elements in the video.
Key Steps for ModelScope Configuration
Select the Text2Video Extension: Start by selecting the text2video extension in the AUTOMATIC1111 Stable Diffusion GUI. If the extension is not integrated, install it as necessary.
Choose the Right Video Size: Use the model with a 256×256 video size for ideal results. This ensures compatibility with the chosen Stable Diffusion checkpoint.
ModelScope Noise Decomposition
ModelScope’s noise decomposition is vital for adding frame consistency and dynamic elements. The base noise remains consistent across all frames, providing a foundation for the video’s structure, while the residual noise varies in each frame, injecting variability and detail.
Video Generation with ModelScope
ModelScope provides a consistent and efficient way to generate videos from text prompts, making it valuable for content creators and researchers. By following these steps and leveraging the model’s noise decomposition technique, you can achieve high-quality video generation with consistent frames. The technology supports High-Resolution Videos, similar to Stable Video Diffusion, which generates high-resolution videos at 576×1024 resolution.
Leveraging ModelScope’s Capabilities
Using a 256×256 video size and integrating the text2video extension ensures that ModelScope generates coherent video sequences with minimal noise, enhancing the overall quality of the generated videos.
Technical Overview
ModelScope’s architecture includes a text feature extraction sub-network, a text feature-to-video latent space diffusion model, and a video latent space to video visual space conversion process. This structure enables the model to transform textual input into visual video frames with high fidelity and coherence.
Applications of ModelScope
The technology has diverse applications, including content creation for marketing, entertainment, education, and social media. It allows users to quickly produce video content without the need for extensive video editing skills.
This makes it a versatile tool for various industries.
Customization Options
Users can adjust the seed for randomness, number of frames for video length, and number of inference steps for video quality. This flexibility enables users to tailor their video generation according to specific needs and preferences.
Ethical Considerations
When using ModelScope, it is essential to avoid generating harmful, demeaning, or false content. Ensuring that the technology is used responsibly and ethically is crucial.
Technical Requirements
For optimal performance, ModelScope requires a computer with 16GB of CPU RAM and 16GB of GPU RAM. Additionally, it requires Python and specific packages like ModelScope, Open_clip_torch, and Pytorch-lightning.
Limitations and Compatibility
AnimateDiff is a technique that turns a text prompt into a video using a Stable Diffusion model, but it currently only works with Stable Diffusion v1.5 models Model Compatibility.
Conclusion
ModelScope offers a robust platform for text-to-video generation. It combines advanced AI techniques with a user-friendly interface.
Its versatility, customization options, and ethical guidelines make it a valuable resource for content creators and researchers seeking to harness the power of AI in video production.
Deforum for Videos
Deforum for Video Generation
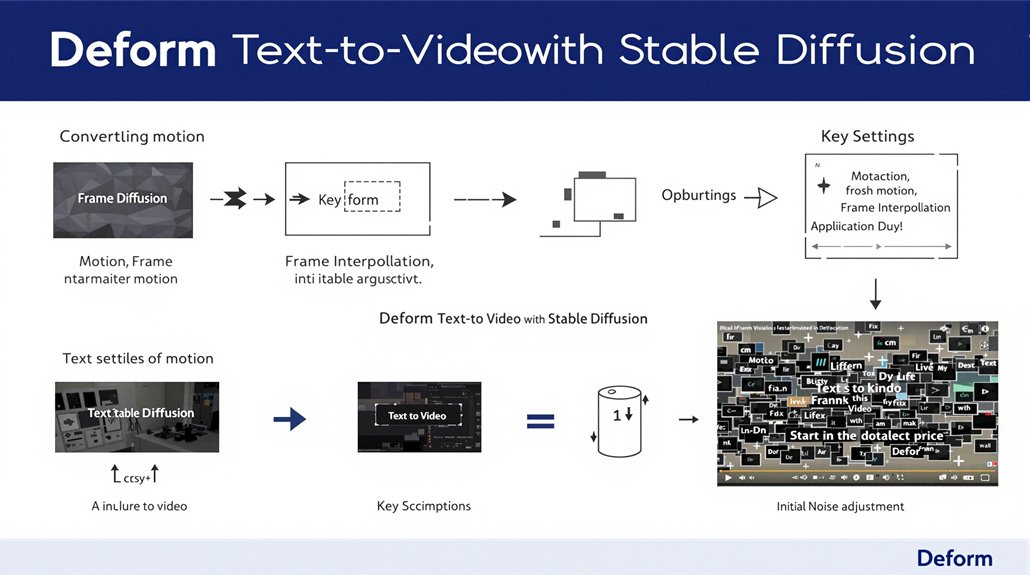
Deforum is a tool that uses Stable Diffusion to generate videos from text prompts. It achieves video consistency by applying the img2img function across frames, utilizing multiple text prompts as input. This ensures that each frame is generated based on its predecessors, resulting in coherent animation.
Key Features of Deforum
Deforum’s functionality relies on creating frames with consistent visual elements. Motion settings such as 2D and 3D transformations can be applied to images to create the illusion of motion.
Frame interpolation can be used to extend video length and enhance overall video quality. To prevent flickering in generated videos, it is essential to adjust the initial noise multiplier to 0.0 in the ‘shared.py’ file Initial Noise Adjustment.
Compatibility and Accessibility
Deforum is compatible with various Stable Diffusion checkpoint models and LoRA, ensuring flexibility and adaptability for different video applications. It can be run on personal hardware, making it accessible to a wide range of users. Deforum’s performance is currently limited by high VRAM requirements VRAM Limitations, which may be improved in future updates.
Detailed guides and tutorials are available, making setup and use straightforward.
Text-to-Video Applications
Deforum is an ideal tool for converting text descriptions into visually consistent videos. It offers a streamlined process for users to create high-quality videos from text prompts, making it a versatile tool for various video creation needs.
Stable Diffusion and frame interpolation are key components in achieving smooth and coherent video animations.
Selecting Stable Diffusion Models
Key Considerations
When selecting Stable Video Diffusion models, two primary variants are available: those generating 14 frames and those generating 25 frames at a resolution of 576×1024 with customizable frame rates between 3 and 30 frames per second.
The SVD-XT model is a finetuned version offering more frames and has demonstrated superior performance in user preference studies, outperforming leading closed models.
Understanding Model Capabilities
Current Stable Video Diffusion models are primarily designed for image-to-video conversion but can be extended for text-to-video through additional interfaces and applications. An upcoming text-to-video interface promises to showcase practical applications in various sectors. These models are built on the foundation of Stable Diffusion, signifying a notable leap in open-source video synthesis capabilities.
Feedback and Model Development
User feedback on safety and quality is critical for refining these models, as they are currently intended for research and not commercial use. Your input helps refine these models for future releases. Diffusion models are rapidly improving due to advancements in conditional generation techniques.
Practical Applications
Stable Video Diffusion models can be used in various sectors such as advertising, education, and entertainment. They offer a versatile tool for transforming text and image inputs into vivid scenes.
Model Specifications
Resolution: 576×1024
Frames: 14 or 25
Frame Rate: Customizable between 3 and 30 FPS
Video Duration: 2-5 seconds
Processing Time: 2 minutes or less
Choosing the right model depends on the specific needs of your project, whether it’s for generating short, dynamic videos or for more detailed, longer scenes. Understanding the capabilities and limitations of Stable Video Diffusion models is key to leveraging their potential effectively.
Configuring Video Settings
Optimizing Video Settings
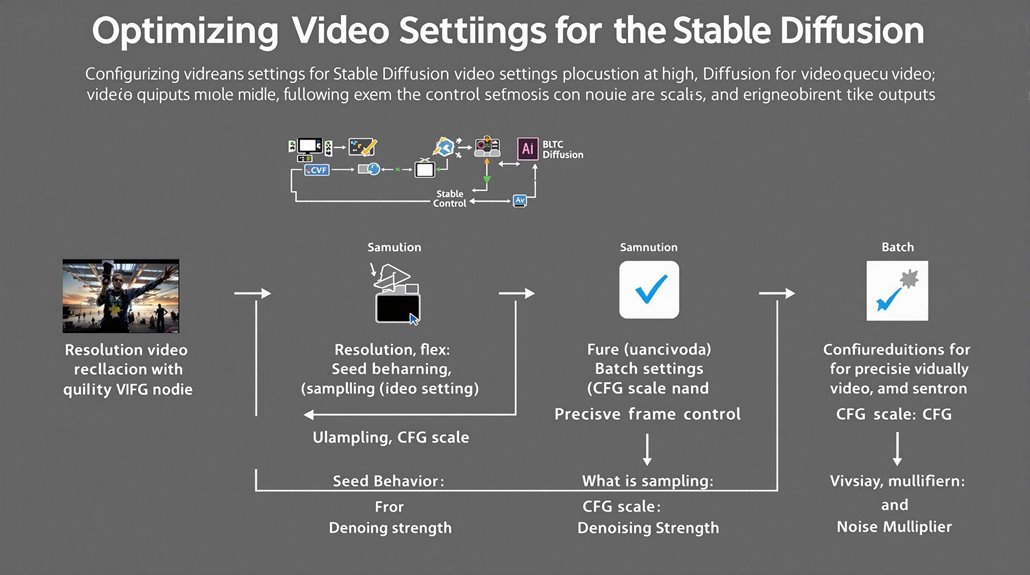
Configuring video settings is crucial for achieving high-quality video outputs with Stable Video Diffusion models. Key parameters include resolution, sampling, seed behavior, and batch settings.
Use a consistent resolution like 512×512 pixels for best results. Sampling settings control video quality and consistency, and understanding these settings is essential for high-quality output.
CFG Scale and Denoising Strength
CFG scale determines how closely the video follows the prompt, while denoising strength regulates how much the video is altered. Setting the noise multiplier to 0 helps reduce flickering.
By adjusting these settings, users can achieve precise frame control and visually coherent video outputs. Utilizing scripts such as ControlNet M2M Script, which automates frame conversion, can significantly enhance the video generation process.
Batch Settings and Processing
Batch settings allow for control over the generation process, ensuring efficient processing and consistent results. Managing seed behavior is also indispensable for maintaining visual coherence throughout the video.
Video Quality and Consistency
Understanding and adjusting video settings are critical for achieving high-quality video outputs. Consistent resolution and sampling settings are key to maintaining video quality and coherence.
Carefully adjusting CFG scale, denoising strength, and noise multiplier ensures precise frame control and visually appealing video outputs.
To ensure efficiency, it’s essential to preprocess the video by resizing it to a more manageable size and transforming it into a square format, such as Uniform Aspect Ratio.
Generating Videos
Generating high-quality videos with Stable Diffusion models involves complex interplay of advanced technologies and meticulously calibrated settings. Central to this process are diffusion models like Stable Video Diffusion and VDM, which extend image generation capabilities to videos by incorporating temporal layers for dynamic video sequences.
Key technologies such as latent diffusion and fine-tuning play vital roles in achieving video quality. Pre-training on diverse images followed by re-training with videos guarantees that models can generate realistic and contextually rich videos.
Temporal layers ensure frame consistency and smooth flow between frames over time. Furthermore, the use of micro-conditioning parameters allows for more precise control over video generation, enabling fine adjustments to aspects like motion and noise levels.
Stable Video Diffusion models, available on Hugging Face libraries, enable practical applications including text-to-video interfaces for sectors like advertising and education. Effective use of these tools requires precise calibration of settings and a deep understanding of the underlying technologies.
To generate high-quality videos, users must optimize frame consistency and video resolution. Tools like AUTOMATIC1111 Stable Diffusion GUI help in achieving this by providing bespoke settings for various video applications.
Incorporating temporal convolution and attention layers, Stable Video Diffusion ensures that generated videos have natural and fluid motion. This technology offers versatile video generation capabilities that can be fine-tuned for different applications.
Compared to text-to-image models, text-to-video models like Stable Video Diffusion require significantly more computational resources to ensure both spatial and temporal consistency across video frames.
Improvement Techniques

Video Quality Improvement Techniques in Stable Diffusion
Frame Improvement
Improving video quality in Stable Diffusion models requires various techniques, particularly those focused on frame enhancement. Temporal Consistency is crucial for maintaining coherence across frames.
Temporal Consistency is achieved by using larger context batch sizes to capture long-range dependencies in the video sequence. This technique ensures that the model understands the flowing nature of the video, reducing inconsistencies. Recent advancements in zero-shot text-to-video synthesis have shown that enriching latent codes with motion dynamics helps maintain temporal consistency across frames. Furthermore, it is essential to utilize free Google Colab credits, which can be refreshed or purchased if exhausted, making it accessible to create high-quality videos Google Colab credits.
Motion Enhancement
Another critical area is Frame Interpolation, which involves adding intermediate frames to increase the frame rate, thereby reducing motion blur and jitter.
For example, converting a 30fps video to 60fps significantly enhances visual smoothness.
Style and Aesthetics
Stable Diffusion also offers sophisticated techniques for enhancing style and aesthetics. Tools like Stable Diffusion upscaling can be used to improve video resolution, making them more visually appealing.
For instance, using stable diffusion software along with additional tools like GFP Gan and Krita can upscale videos to higher resolutions, providing a straightforward yet effective process.
Performance Optimization
Performance optimization is another critical aspect. Model Selection plays a significant role, with models like the A100 offering faster rendering speeds and more efficient processing of the Stable Diffusion algorithm.
Choosing the right model can significantly impact the final output quality and processing time.
Practical Applications
Stable Video Diffusion: Transforming Industries with AI-Driven Video Content
Versatile Capabilities Across Industries
Stable Video Diffusion is a groundbreaking AI tool that converts static images into vibrant videos, offering vast possibilities for media, education, and marketing. It generates short videos with customizable frame rates up to 30 FPS, allowing for robust video representation suitable for various tasks like text-to-video synthesis and multi-view synthesis.
This AI model is highly adaptable and can be used in multiple industries due to its versatile capabilities.
Educational Applications
This AI model can create engaging video materials, empowering users to create live-action videos that enhance learning experiences with natural and fluid motion. This makes educational content more immersive and interactive.
The interactive nature of these videos can significantly improve student engagement and understanding.
Marketing Strategies
Stable Video Diffusion offers a Text-To-Video interface, generating short, high-quality videos for marketing campaigns with customizable frame rates. Its adaptability to various downstream tasks, including advertising, makes it a valuable tool for creating engaging video content.
The flexibility in customization allows marketers to tailor their video content to specific audience needs.
Cross-Industry Compatibility
Its high-resolution output and seamless integration with popular video editing software make it a versatile tool for various sectors. Stable Video Diffusion‘s AI-powered video generation capabilities make it a promising tool for creating cinematic and engaging content.
This compatibility ensures that the tool can be integrated into existing workflows without significant disruption.
Key Features
AI-Powered Video Generation: Converts static images into dynamic video sequences.
High-Resolution Output: Suitable for professional use.
Customizable Settings: Adjustable parameters for diffusion effects and video quality.
Real-Time Preview: Allows users to preview video effects and adjustments.
Template Library: Includes templates for different video styles and formats.
Impact on Creative Industries
Stable Video Diffusion can significantly impact creative industries by providing a tool for rapid and diverse video content creation. It enhances creative processes in filmmaking, advertising, and digital art.
The tool’s ability to generate high-quality videos quickly can accelerate project timelines and increase productivity in these sectors.
Technical Efficiency
The model’s processing time is notably efficient, with videos generated in 2 minutes or less, making it suitable for time-sensitive projects.